How similar is the execution of Java and JavaScript?


Alex Woods
April 14, 2019
Java and JavaScript are two of the most popular languages out there. On the surface, their execution is very different—one being interpreted and the other running on this important platform called the JVM. But how different are they?
Execution at the processor level
With each passing clock cycle, the processor executes a single microinstruction. These are strings whose bits drive the control lines of the CPU. We get a series of microinstructions by the translation of an instruction (frequently called machine code). The set of all available instructions for a processor is called the Instruction Set Architecture (ISA), which in a sense is the API of your computer’s processor.
source code -> instructions (now within processor) -> microinstructions (executed each clock cycle)
Statements in a program can be taken by a compiler and turned into machine code (instructions). The best example of this is C. Different processors, however, provide different Instruction Set Architectures. Does this mean we have to write a different compiler for each processor? (Yes, it does.) This is a problem as compiler’s do more and more work for the programmer.
We can solve this by keeping all the added features in our program executor the same, except for the processor. If we virtualize the processor, and provide an ISA specially designed for the execution of the language in question, we now have a component we can take in and out, as we move from one OS to another (presumably with different processors).
Virtualizing the processor
As alluded to above, both the languages in question (Java and JavaScript), provide an abstraction on top of machine code in order manage this complexity. This “abstraction of machine code” is called bytecode. In Java, it is the .class files, and with JavaScript it varies depending on the engine in question. To see the bytecode used by the V8 engine (the one used in Node.js and Chrome), execute it with the --print-bytecode flag.
To run a JavaScript program purely with V8 (excluding Node’s runtime), install V8 and run v8 hello.js (where hello.js is your program)e.g. v8 --print-bytecode hello.js (Because seeing the bytecode of Node’s runtime isn’t the best for education purposes).
When I say “virtualizing the processor”, what I mean is that we are executing the program in a virtual machine. We have some entity (either the JVM interpreter or the Ignition bytecode executor), that knows how to execute their version of bytecode. What we are using here is called a process virtual machine. This is in stark contrast to a system virtual machine, which has its own guest operating system (think VMWare). A process virtual machine is much lighter, and its sole purpose is executing a program. To be clear, it does further virtualize other things, such as memory, which means there exists a mapping. For simplicity, the mapping is just a direct mapping. Note that memory is already virtualized on the host OS; the memory blocks given to a process appear continuous, but are not guaranteed to be so. The most complicated thing we are abstracting away is the processor and it’s machine code.
In the JVM, for example, the interpreter takes a line of bytecode, and knows how to execute it without providing further translation into machine code.
In V8, the Ignition interpreter acts in a similar way. it takes a statement from the parsed AST, turns it into bytecode, and executes it by itself.
Let’s dive deeper into the details of the two.
How the JVM Executes Programs
Let’s say we have some Java source code. We use the Java compiler (javac) to turn it into bytecode (.class files). Then we feed it into the JVM.
The JVM takes it, and after some initialization steps (class loading, bytecode verifying, etc.), a statement of bytecode arrives at the interpreter, which executes it.
As execution continues, if some piece of code (e.g. a function) has been executed a certain number of times (i.e. it is “hot”), the JVM execution engine contains a JIT optimizing compiler which will turn it into machine code, allowing it to execute faster.
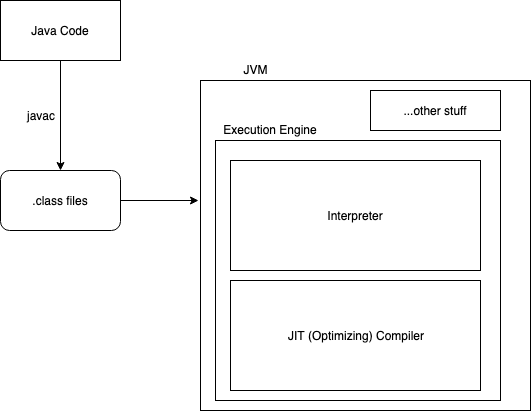
Note that the “JIT compiler” in this case goes from bytecode to machine code. JavaScript’s JIT compiling, in contrast, goes from source code to bytecode.
How the V8 Engine Executes Programs
In contrast, JavaScript is JIT compiled. That means there is no pre-compilation step before it is fed into the execution engine; we feed the engine raw source code.
Say, we have some JavaScript source code. It is parsed and turned into an AST. That is then fed into Ignition, V8’s interpreter. Ignition turns that into bytecode, and executes it.
Just like before, if we discover a hot function, we have an optimizing compiler to turn that into machine code. In V8, this entity is called TurboFan.
Going to steal Franziska Hinkelmann’s picture, from her great blog post on the topic.
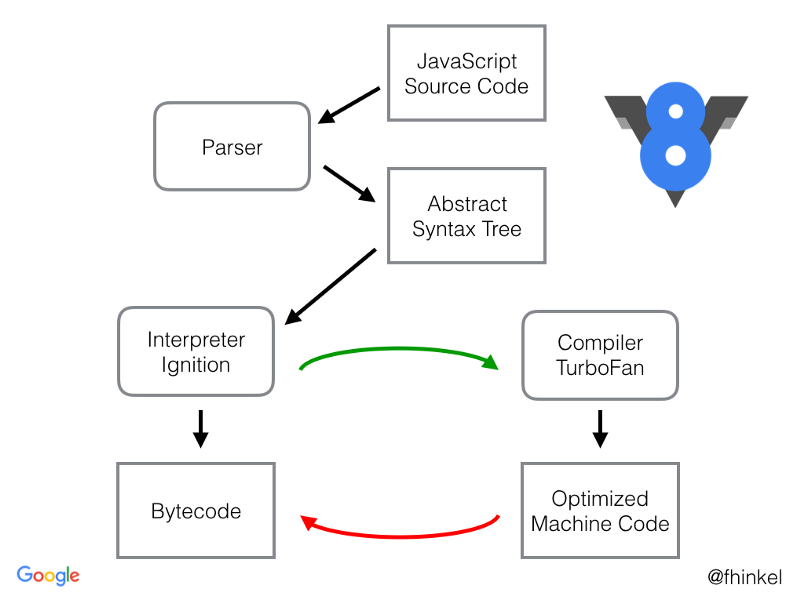
Note – Above I talked about process virtual machines. V8 is pretty sparse on those kind of internal details, but I did read enough to convince myself that they use a process virtual machine. (See here, here, and here).
Similarities Between Java and JavaScript Execution
- Both are run inside process virtual machines. They both have their own “bytecode”, which is just an abstraction of machine code. Those process virtual machines execute their corresponding bytecode.
- They both take the same approach for code that is “hot”. That is, an optimizing compiler turns the bytecode into machine code, using profiling information accumulated throughout execution.
Differences Between Java and JavaScript Execution
There is one major difference here—JavaScript is JIT compiled, Java is not. Due to this, there’s no abstraction in between the JavaScript language and it’s execution engine (V8, in this case). That means it’s impossible to use V8 to execute another language.
The JVM, on the other hand, only knows about .class file bytecode. This gives space for other language that can compile to .class files. Enter Scala, Groovy, Clojure, and Kotlin.
It’s ironic because this layer of abstraction only exists because there was a necessity to send bytecode over the network, around the time Java came out (early World Wide Web days, when Java was supported in the browser). Nowadays, this doesn’t matter at all. These days we send JavaScript source code over the network, and the browser uses an execution engine (like V8) to execute it.
I find this point fascinating, and I believe this indirection might lead to the JVM sticking around for a very long time, because we can choose to use it even if we don’t want to use Java. It’s appealing for language designers, because over half the work is done for them—all they have to do is design a language spec and a compiler to .class bytecode.